Unix Named Pipes are a cool feature as they help you avoid writing the data to disk and hence speed up the performance significantly. More info on Named Pipes can be found here.
Let’s create our own named pipe, which is really quite easy:
mkdir named-pipe
cd named-pipe
mkfifo my-named-pipe
Next we just generate a sequence and feed it into the named pipe:
seq 1 15000 > my-named-pipe
The last command will just hang in there until you actually finish reading from the named-pipe with another process. You could also just send the last command/process into the background by suffixing it with an ampersand (&).
Let’s create a super simple PDI transformation with a Text input step and a Write to Log step. Set the file reference in the Text input step to named pipe file we just created, e.g.:
/Users/diethardsteiner/projects/named-pipe/my-named-pipe
Make sure you also disable the header row setting etc (apply common sense settings). And now you are ready to go, just run the transformation from within Spoon to test it and you should see the sequence numbers flowing in:
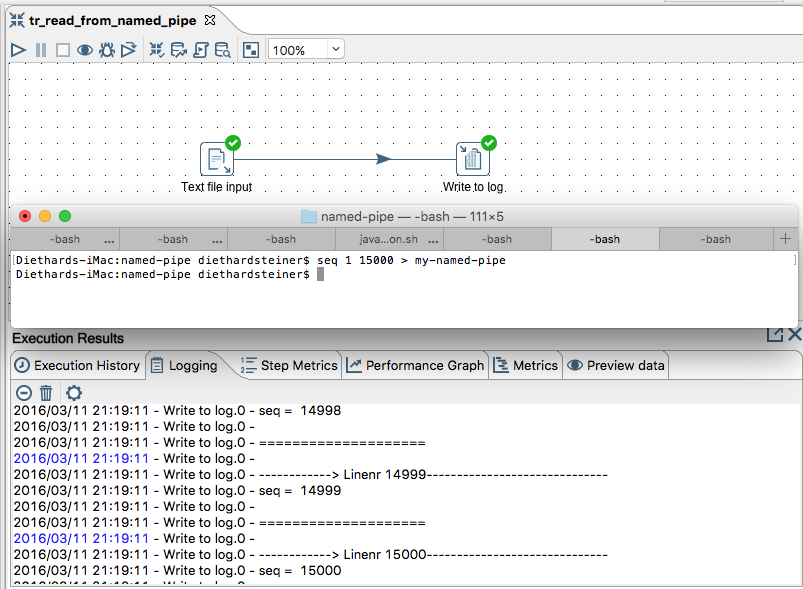
Once the transformation execution finishes, you will also notice that the seq command finished in the Terminal. Excited as we are, let’s start this command again and now from another terminal window we execute the transformation, e.g.:
sh /Applications/Development/pdi-ce-6.0.1/pan.sh -file=/Users/diethardsteiner/Dropbox/development/code-examples/pentaho/PDI/tr_read_from_named_pipe.ktr
Finally, if you do not want to use the named pipe any more, you can just remove it like a normal file:
rm my-named-pipe
Now this proved all to be fairly simple to set up and could come in handy in various situations!