Parameters and variables in Pentaho Data Integration are a slightly complex topic, which I covered in a few blog posts previously. My previous blog post on this topic focused on creating a JSON like object to store such parameters - while this was an interesting exercise, it is not a very practical approach. I shall explain a more elegant solution today.
Passing parameters from the command line / shell scripts and having them set up in the job/transformation settings is a suitable setup for smaller processes. Once you start creating jobs called by master jobs which in turn get called by grand master jobs (and so forth), passing down parameters becomes a non trivial job, especially if these jobs are still supposed to work on their own.
Let’s explain the new strategy:
- Jobs are a must: Every transformation has to be executed by a job. Think of this as a wrapper job.
- Properties Files: Every job has its own (only it’s own) parameters stored in a properties file of exactly the same filename as the job name. This way we can simply reference the file by reference:
.properties. Just to emphasis this again: We only store parameters in this file which are required for this one particular job, unless we want to overwrite the parameters of a sub-job! This is important to understand as this helps keeping the maintanance easy, e.g. the lowest level job has a parameter calledVAR_DATE, we do not want to have to define this parameter for the master and grand master job e.g. - unless we want to overwrite its value! - Precedence: As mentioned previously, if a parameter of a sub-job is explicitly define in a parent job (or any ancestor for that matter), we want it to take precedence over the local parameter.
We will make Kitchen, Pan and Spoon environment and project aware:
| Variable | Description |
|---|---|
PROJECT_NAME |
Name of the project |
PROJECT_HOME |
Path to the root folder of the project |
PROJECT_ENV |
Environment (dev, test, prod, etc) |
Open spoon.sh in a text editor and add following paramters to the OPT section:
-DPROJECT_NAME=$PROJECT_NAME -DPROJECT_HOME=$PROJECT_HOME -DPROJECT_ENV=$PROJECT_ENV -DPENTAHO_METASTORE_FOLDER=$PENTAHO_METASTORE_FOLDER
For PDI-CE-6.1 this should look like this then:
OPT="$OPT $PENTAHO_DI_JAVA_OPTIONS -Dhttps.protocols=TLSv1,TLSv1.1,TLSv1.2 -Djava.library.path=$LIBPATH -DKETTLE_HOME=$KETTLE_HOME -DKETTLE_REPOSITORY=$KETTLE_REPOSITORY -DKETTLE_USER=$KETTLE_USER -DKETTLE_PASSWORD=$KETTLE_PASSWORD -DKETTLE_PLUGIN_PACKAGES=$KETTLE_PLUGIN_PACKAGES -DKETTLE_LOG_SIZE_LIMIT=$KETTLE_LOG_SIZE_LIMIT -DKETTLE_JNDI_ROOT=$KETTLE_JNDI_ROOT -DPROJECT_NAME=$PROJECT_NAME -DPROJECT_HOME=$PROJECT_HOME -DPROJECT_ENV=$PROJECT_ENV -DPENTAHO_METASTORE_FOLDER=$PENTAHO_METASTORE_FOLDER"
We have to set the basic PDI related variables as well as define the environment (dev, test, prod etc). These are config properties that will be very likely applicable to most projects running on the server:
| Variable | Description |
|---|---|
PROJECT_ENV |
Environment (dev, test, prod, etc) |
KETTLE_HOME |
Directory where PDI stores its config files etc |
DKETTLE_JNDI_ROOT |
Directory where you store the JNDI defs |
PENTAHO_METASTORE_FOLDER |
Directory for the Pentaho Metastore |
PDI_HOME |
PDI root directory |
Add this to the bashrc or bash_profile file:
# ADD THIS TO BASHRC OR BASH_PROFILE
# ENVIRONMENT
export PROJECT_ENV=dev
echo "- PROJECT_ENV: " $PROJECT_ENV
# KETTLE HOME LOCATION
export KETTLE_HOME=$PROJECT_HOME/config/$PROJECT_ENV
echo "- KETTLE_HOME: " $KETTLE_HOME
# JNDI FILE LOCATION
# KETTLE_JNDI_ROOT is only availble in the spoon shell scripts as of version 5. For an earlier version, add the following to the OPT section in spoon.sh: -DKETTLE_JNDI_ROOT=$KETTLE_JNDI_ROOT
export KETTLE_JNDI_ROOT=$PROJECT_SHELL_SCRIPTS_FOLDER/../config/$PROJECT_ENV/simple-jndi
echo "- KETTLE_JNDI_ROOT: " $KETTLE_JNDI_ROOT
# METASTORE LOCATION
# Add the following to the OPT section in spoon.sh: -DPENTAHO_METASTORE_FOLDER=$PENTAHO_METASTORE_FOLDER
export PENTAHO_METASTORE_FOLDER=$PROJECT_HOME/config/$PROJECT_ENV
echo "- PENTAHO_METASTORE_FOLDER: " $PENTAHO_METASTORE_FOLDER
# PDI DIR
export PDI_HOME=/Applications/Development/pdi-ce-6.1
echo "- PDI_HOME: " $PDI_HOME
Some of parameters we added to the JVM settings are defined in shell-scripts/set-project-variable.sh, but we will add also a few other ones. This file will be sourced by any other shell file which executes a PDI job - making sure the essential variables get always set. You can think of this file as of containing the core configuration details for a particular project:
#!/bin/bash
echo "SETTING ENVIRONMENT VARIABLES ..."
echo "---------------------------------"
# Define variables
# PROJECT NAME
export PROJECT_NAME=sample-project
echo "- PROJECT_NAME: " $PROJECT_NAME
# get path of current dir based on http://www.ostricher.com/2014/10/the-right-way-to-get-the-directory-of-a-bash-script/
get_script_dir () {
SOURCE="${BASH_SOURCE[0]}"
# While $SOURCE is a symlink, resolve it
while [ -h "$SOURCE" ]; do
DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
SOURCE="$( readlink "$SOURCE" )"
# If $SOURCE was a relative symlink (so no "/" as prefix, need to resolve it relative to the symlink base directory
[[ $SOURCE != /* ]] && SOURCE="$DIR/$SOURCE"
done
DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
echo "$DIR"
}
export PROJECT_SHELL_SCRIPTS_FOLDER="$(get_script_dir)"
export PROJECT_HOME=$PROJECT_SHELL_SCRIPTS_FOLDER/..
To cater for the requirements listed above, we only have the create one jobs and one transformation:
The job which controls the behaviour is called jb_param_set.kjb:
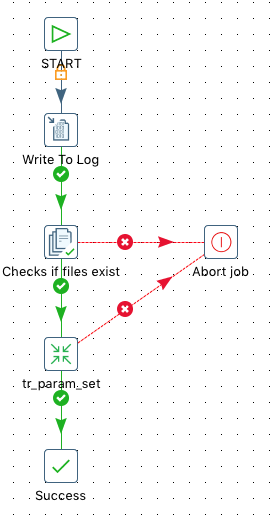
It accepts a parameter called VAR_PROPERTIES_FILE, which allows you to define the filename of the properties file at runtime.
The important bit here is that properties files are expected to be stored in a speciic directory:
${PROJECT_HOME}/config/${PROJECT_ENV}/${VAR_PROPERTIES_FILE}
In this case you create a properties file for each job for each environment.
The job checks if the properties file exists and then calls the tr_param_set transformation:
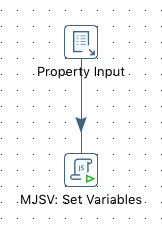
The properties file gets source and then the little and simple magic happens in a JavaScript step:
getVariable(key,"") == "" ? setVariable(key,value,"r") : null
All we do here is check if the variable of the name (key) already exists - if not, we create it. This takes care of the parameter precedence handling.
How to set up a standard job for our parameter logic
Any job you create from now on will have to include the jb_param_set job - once for the project specific parameters and once for the job specific properties. This enables us to store parameters that apply to all jobs and transformations within the project in one file and parameters that apply only to that particular job in another file, which in the end makes maintenance a lot easier. Note that the .kettle/kettle.properties file can store global parameters in such a setup, so for parameters that are used across projects.
In job entry parameter tab for the project specific parameters we define following mapping:
| Parameter | Stream column name | Value |
|---|---|---|
VAR_PROPERTIES_FILE |
${PROJECT_NAME}.properties |
In the job entry parameter tab for the job specific properties we define following mapping:
| Parameter | Stream column name | Value |
|---|---|---|
VAR_PROPERTIES_FILE |
${Internal.Job.Name}.properties |
Only then we implement whatever the job has to do (e.g. call a sub-job etc):
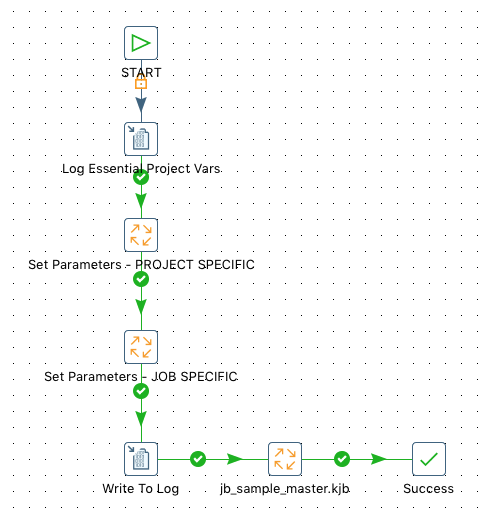
Our sample test setup consists of three jobs and one transformation:
jb_sample_grand_master.kjbjb_sample_master.kjbjb_sample.kjbtr_sample.ktr
Respectively, we create three properties files:
jb_sample_grand_master.properties:
VAR_TEST_0=param-value-set-by-grand-master
jb_sample_master.properties:
VAR_TEST_0=param-value-set-by-master
VAR_TEST_1=param-value-set-by-master
jb_sample.properties:
VAR_TEST_0=param-value-set-by-job
VAR_TEST_1=param-value-set-by-job
VAR_TEST_2=param-value-set-by-job
Important: We only define some of the parameters in the parents here because we do want to test the precendence feature. As stated previously, any properties file is supposed to contain only its own properties, unless you want to overwrite them in the child-jobs.
We also have a project wide properties file called sample-project.properties:
# Define delimiter for text files
VAR_TEXT_FILE_DELIMITER=|
Let’s execute the grand master job (jb_sample_grand_master.kjb), which is supposed to log on each level the value of the available parameters. Let’s pay attention to the log:
2016/06/11 16:10:06 - - ====== GRAND MASTER PARAMETER VALUES ========
2016/06/11 16:10:06 - -
2016/06/11 16:10:06 - - text file delimiter: |
2016/06/11 16:10:06 - - test0: param-value-set-by-grand-master
...
2016/06/11 16:10:06 - - ====== MASTER PARAMETER VALUES ========
2016/06/11 16:10:06 - -
2016/06/11 16:10:06 - - text file delimiter: |
2016/06/11 16:10:06 - - test0: param-value-set-by-grand-master
2016/06/11 16:10:06 - - test1: param-value-set-by-master
2016/06/11 16:10:06 - jb_sample_master - Starting entry [jb_sample.kjb]
...
2016/06/11 16:10:06 - - ====== JOB PARAMETER VALUES ========
2016/06/11 16:10:06 - -
2016/06/11 16:10:06 - - text file delimiter: |
2016/06/11 16:10:06 - - test0: param-value-set-by-grand-master
2016/06/11 16:10:06 - - test1: param-value-set-by-master
2016/06/11 16:10:06 - - test2: param-value-set-by-job
...
2016/06/11 16:10:06 - Write to log.0 - ==== TRANSFORMATION PARAMETER VALUES ====
2016/06/11 16:10:06 - Write to log.0 -
2016/06/11 16:10:06 - Write to log.0 - text_file_delimiter = |
2016/06/11 16:10:06 - Write to log.0 - test0 = param-value-set-by-grand-master
2016/06/11 16:10:06 - Write to log.0 - test1 = param-value-set-by-master
2016/06/11 16:10:06 - Write to log.0 - test2 = param-value-set-by-job
2016/06/11 16:10:06 - Write to log.0 -
2016/06/11 16:10:06 - Write to log.0 - ====================
Note how the parameters from the parent job take precedence.
Important: It is also possible to use PDI parameters in properties files! So you could also do something like this (which might to some extend avoid the need to have one properties file by environment):
# Define path to input file
VAR_INPUT_FILE=${VAR_GIT_ROOT_DIR}/input-files/my-file.csv
Conclusion
The approach illustrated above is very simple to implement and maintain. It provides various scope levels - global, project and job - as well precendence support. Finally, all jobs can be run independently without any changes.
You can download the files from here.