Installation
If not already installed, add the Pentaho PDI Dataset plugin to PDI. You can download a release from here. Add the unzipped folder to <pdi-root-folder>/plugins and restart Spoon if already open.
Once you open a transformation, you should see a flask icon in the top left corner of the canvas in Spoon:

Left clicking on to the flask icon will give you access to all the Pentaho PDI Dataset features/menu items.
Important: The Pentaho PDI Dataset plugin does not work with PDI repositories. In general, as of PDI v7.1, best practice is to develop using files only (no repo) and if required, load it into the PDI repository in production.
Additional Configuration
Most of the unit test configuration details will be stored in the PDI Metastore. By default this is stored in ~/.pentaho/metastore. If you use a custom location for the PDI Metastore the default installation of PDI does not pick up the PENTAHO_METASTORE_FOLDER environment variable. You have to change the OPT section spoon.sh: just add ` -DPENTAHO_METASTORE_FOLDER=$PENTAHO_METASTORE_FOLDER at the end. You can also add the two other parameters related to PDI unit testing: DATASETS_BASE_PATH (path to the folder containing the CSV unit test datasets) and UNIT_TESTS_BASE_PATH (location from which the unit test should be executed from). Alternatively you can define them in kettle.properties` as well.
-DPENTAHO_METASTORE_FOLDER=$PENTAHO_METASTORE_FOLDER -DDATASETS_BASE_PATH=$DATASETS_BASE_PATH -DUNIT_TESTS_BASE_PATH=$UNIT_TESTS_BASE_PATH
Creating a Unit Test
Note: Unit testing is only available for transformations - not for jobs.
Creating Unit Test Data
CSV Files
I recommend storing unit test data in CSV files within the git repository. The Pentaho PDI Dataset plugin can directly read CSV files instead of relying on a shared database connection.
Use the following convention:
- File extension:
.csv - Delimiter:
, - Enclosure:
"(for strings only, not mandatory) - Header row: required
Note: If your data includes double quotation marks (“), then they have to be escaped with yet another double quotation mark (“”).
Database Tables
Best Practice: I recommend storing unit test data in CSV files within the git repository. The PDI Unit Testing plugin can directly read CSV files instead of relying on a shared database connection. So the next section is just for background info.
A prerequisite is that you have a shared database connection within PDI in place. The data for the unit test input and output datasets can be stored in any relational database like MySQL, PostgreSQL etc. You can use an existing shared database connection or create a new one. A database connection is shared, if it shows up in the View panel under Database Connections in bold characters. If this is not the case, right click on the database connection and choose Share.

Creating a Dataset Group
The first thing we have to set up is a dataset group, which mainly specifies the database connection or the folder location of the unit test data that should be used.
Left click on the flask icon and choose Data Set Groups > New Group:

Provide a name for the group, description and then pick CSV as the Data set group type. This will enable us to source CSV files from a Git repo instead of relying on a database. Finally provide the path to the folder containing the CSV files.
Use can set the environment variable DATASETS_BASE_PATH to point to the folder containing the CSV files. If you set DATASETS_BASE_PATH you don’t need to specify it in the dataset group. (In fact currently specifying a parameter for this folder in the dataset group dialog does not work - Github Issue.

If you opted to choose a database instead of CSV files, define the database connection and a schema name instead (last one is not required for all databases). If the Database pull down menu is not populated, you forgot to share the database connection.
Creating Unit Testing Datasets
In general for each transformation you want to have at least one unit test input dataset and one golden output dataset. The input dataset depicts how the data should look like as the output of your very first step of the transformation, whereas the golden dataset depicts the output of the final step of your transformation.
There are a few ways to create these datasets:
Manually Define The Dataset
Left click on the flask icon and choose Data Sets > New data set:

Provide the name, description, table name (as stored in the unit testing database or if CSV file, just the file name without the extension) and pick one Data Set Group. Finally, define the metadata of the table. The field name is the name of the field within the PDI transformation whereas the column name is the actual column name in the database or CSV file (this allows you to do a mapping between the PDI and outside world).
There is also an option to have PDI generate the DDL (CREATE TABLE statement) for the database table: Click on the Create Table button. Amend it if required and then execute it.
Note: If you are working in a locked down environment where e.g. you don’t have access direct access to the database and want to attach a dataset to the Table Input step, make sure that when you define your unit test dataset, that the field column is set to the same name as the field returned by the Table Input step (because since PDI without a working DB connection cannot source any metadata, all the Pentaho PDI dataset plugin can rely on is this mapping that you provide in the dataset dialog).
Derive Dataset Metadata from the Step Metadata
Right click on the relevant step in your transformation and choose Unit test > Define data set with step output. The next steps are similar to the ones descriped in the previous section.
Creating a Unit Test
Note: A transformation can have more than one unit test.
Left click on the flask icon and choose New Unit Test:
Provide the name, description, type of test and base test path. Last one should be defined via the predefined ${UNIT_TESTS_BASE_PATH} parameter. Depending on your setup you might also have to specify other settings. Click Ok.
Note: If you use any other parameter name than
UNIT_TESTS_BASE_PATHthe unit test will not be visible in Spoon. It is recommended that you stick to usingUNIT_TESTS_BASE_PATH. If you ever used a different parameter and want to revert the situation, just navigate on the terminal to the location of the metastore and find the related XML file for your unit test. Open it in a text editor and replace the parameter.
Note:
UNIT_TESTS_BASE_PATHwill usually point to the folder where all your jobs and transformations are stored. If your transformation is stored in example in${UNIT_TESTS_BASE_PATH}/base-layer, then in your unit test you have to define the base as:${UNIT_TESTS_BASE_PATH}/base-layer, so it has to point exactly to the same folder as your transformation is stored in.Note: If the absolute hardcoded path is used and for some reason the directory is not available any more (e.g. it got delete or you switch to a different laptop with a differen file system structure), Spoon tends to freeze when loading the transformation. Resolve this by editing the unit test xml file in
${PENTAHO_METASTORE_FOLDER}/metastore/pentaho/Kettle Transformation Unit Test. You will want to adjust the path listed in thetransformation_filenamesection. I usually tend to define the relative path from the${UNIT_TESTS_BASE_PATH}, e.g../utilities/tr_get_current_time.ktr.
Define Input and Golden Output Dataset
Right click on the relevant transformation input step and choose Unit test > Input data: Select a data set. Right click on the relevant transformation output step and choose Unit test > Golden data: Select a data set.
Note: Once you defined the mapping from your unit test dataset to the stream data, you will be also asked in the next step to define a sort order for the data in your unit test dataset: By default this is prepopulated with all the fields from your unit test dataset. Just delete the ones that you don’t require to be sorted. You can also delete all the fields so to not to define any sort order at all.
Your steps should then have labels attached to them like shown in the screenshot below:

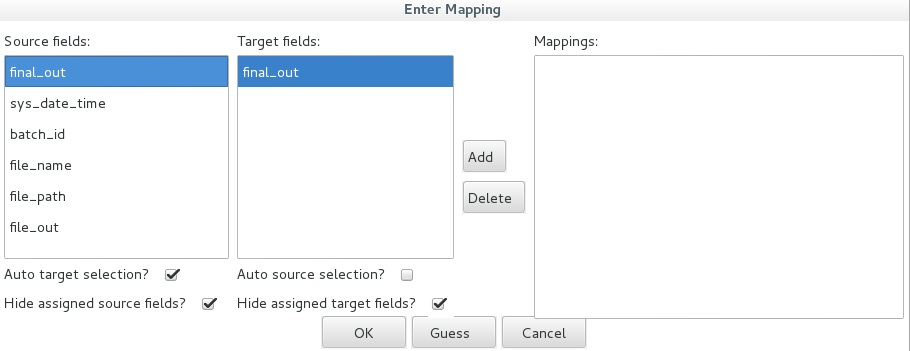
Mapping only certain fields for Golden Dataset
In some scenarios it might not be possible to test all the generated fields of a stream with the golden dataset: Your transformation could generate UUIDs, current time, file paths based on dynamic elements etc. Currently it is impossible to unit test these elements. You can do not have to, however, always map all the fields of a given output step to the golden dataset! Example: Our transformation generates a JSON file. Because the JSON structure is rather complex we do not use the native JSON output step, but generate the JSON via a JavaScript step and feed the result into the Text Output step. Apart from these, we also pass on metadata, like the output path of the file etc. When we attach the golden dataset to the Text Output step, in the mapping, we only map final_out (which contains the JSON content), but no other fields. This will be sufficient to perform our unit test.
Where has my Unit Test gone?
The next time you open your transformation you might wonder why the unit test name and the input and golden output dataset labels are not shown. Don’t you worry, your unit test configuration is not lost, you just need to pick the correct unit test from the flask icon like so (Switch > Unit Test Name) to show the details:

Disabling Unit Testing for the Current Transformation
In Spoon, once you switched to a unit test, the datasets associated to this unit test will be injected into the transformation. Sometimes you might want to go back to the default mode (having no unit testing enabled): In this case, simply left click the flask icon and choose Disable:

Executing the Unit Test
In the simplest case you can just execute the transformation with the unit test enabled and you will see some additional lines printed at the end of the log like these ones:
2018/11/08 11:31:49 - tr_main - ----------------------------------------------
2018/11/08 11:31:49 - tr_main - Select values - tr_main_output_case_1 : Test passed succesfully against golden data set
2018/11/08 11:31:49 - tr_main - Test passed succesfully against unit test
2018/11/08 11:31:49 - tr_main - ----------------------------------------------
But really you want to automate all the unit tests and get a result set back. The way to do this is to create a separate transformation and use the Execute Unit Tests step. This one will find all the defined unit tests (they are actually stored in the PDI Metastore) and run them all. There is not much to configure on this step, just the Type of tests to run. The output of this step could be e.g. further transformed into a format that a CI Tool like Jenkins understands and then the whole process can be fully automated.

Using the Pentaho PDI Datasets for Development without Connecting to External Data Sources
The Pentaho PDI Dataset plugin is not only useful for unit testing, but can help you develop the skeletons of a transformation in locked down environments (e.g. if you workstation does not have access to the environment where the database is located in). In this case you can just simply create a unit test and attach datasets to the input steps only. Whenever you add a new step to the stream, you can use the standard step preview functionality. Certainly this does not test your transformation completely (since the input data is simulated), but it at least helps you get moving on your development efforts.
Example Repo
I provide a very simple example repo(code repo and config repo) on GitHub so that you can see how this plugin is used in practice.
Advanced Info
Where are my unit tests stored?
In previous versions of the Pentaho PDI Dataset plugin the settings were stored in the PDI Metastore as well as in the PDI transformations and jobs. Since the plugin is not officially supported, a suggestion by the community to remove the settings from the jobs and transformations was accepted by the plugin developer (original PDI founder and core developer Matt Casters) and these days the settings are only stored in the PDI Metastore. By default this one is located in ~/.pentaho/metastore, however the location can be changed via the predefined PDI parameter PENTAHO_METASTORE_FOLDER.
Bugs and Errors with the Plugin
Please create tickets for them here.
Suggested Naming Conventions - Best Practice
For any names we have to make sure that they do not collide across developers, since these artifacts are all stored within the same metastore folder per type.
Data Set Groups
They can be used across transformations, so my simple thinking is that we just define one by unit testing datasource (e.g. the database where the unit test data is stored or the folder where the unit test datasets are stored as CSV files). In our case all the test data is stored in CSV files within a dedicated Git repo folder (e.g. /home/myuser/git/pdi-unit-test-example/pdiute-code/pdi/unit-test-datasets), in which case we can just use one data set group across all developers for a given project. Convention:
[PROJECT-ACRONYM]_unit_test_data (all lower case)
Unit test
Every test will have a purpose, as opposed to being generic. It can be described as expected behaviour if it’s the happy path. Unhappy paths would have something specific to cause a failure and exercise error handling. (thanks to Miles for suggesting this)
Given following artifact names:
- Transformation:
tr_my_trans - Unit test:
my_first_unit_test
The resulting Unit test name is: tr_my_trans-my_first_unit_test (use hyphens to separate artifact names).
It is mandatory to add a description to the unit test to explain what are we actually trying to test with this unit test. You might write a specific unit test to test a certain edge case scenario: It would be good for someone new to understand what exactly that edge case scenario is.
It is mandatory to set the type of test to Unit test for the unit test definition.
Dataset
We can have more than one unit test by transformation, so we should add the unit test name as well to the dataset name. The disadvantage is that we end up with a rather long name.
Given following artifact names:
- Transformation:
tr_my_trans - Unit test:
my_first_unit_test - Step name:
MySQL Country Data
The resulting …
- dataset name (as defined within Spoon):
tr_my_trans-my_first_unit_test-mysql_country_data(use hyphens to separate artefact names) - CSV file: either name the file exactly the same as the dataset name (e.g.
tr_my_trans-my_first_unit_test-mysql_country_data.csv) store in folders like sotr_my_trans/my_first_unit_test/mysql_country_data.csv. You can in fact define paths as well as part of the dataset definition - it works just fine.