So PDI these days supports Metadata Injection for a variety of transformation steps.
Metadata Injection: In layman’s terms … Imagine you have to ingest 10 different spreadsheets. All of them have a different structure. Traditionally you would create 10 ETL transformations for this purpose. When the 11th spreadsheet comes along, you would have to create just another one. Well, that’s not fun! Instead, these days you create a transformation template and just tell it what structure your spreadsheet is in (all the column names and types etc) - the metadata so to speak. So you have one transformation and can then import an indefinite number of different spreadsheets. This was just an example. This can be applied to anything (well, all the steps that support Metadata Injection in PDI, of which there are luckily many these days). Pure efficiency you might say!
That’s all well and good - you might say - but I still have to manually supply the metadata?! I still can’t build a fully automated solution, throw any content at it and it will process it? Like pure magic?! Yes, you can!
PDI comes bundled with a few steps that allow you to extract metadata from files, streams or database tables. There are also several steps available on the Marketplace that cater for this need. We will discuss a few of these steps here:
How to get file metadata
Following steps are available:
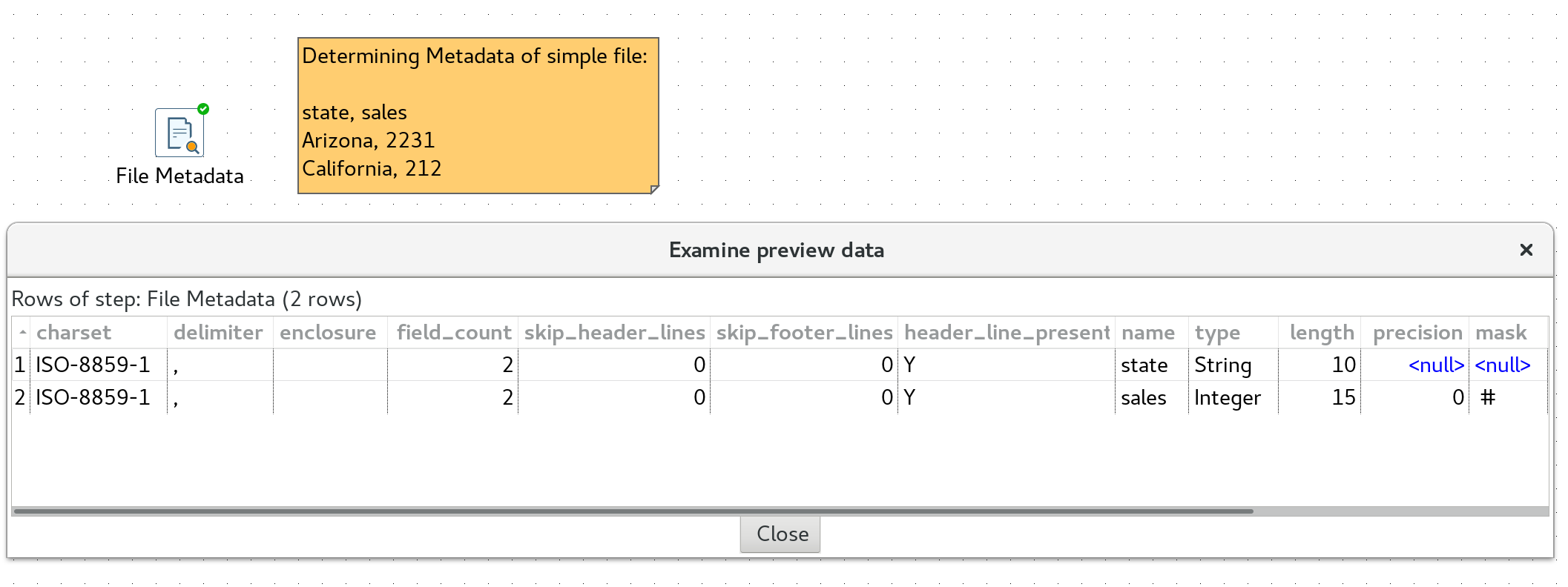
Get File Names- Does what is says on the tin. No surprises here!File Metadata(from the Marketplace, or alternatively GitHub)
This step utilises libraries from the Apache Tika project a “toolkit [that] detects and extracts metadata and text from over a thousand different file types (such as PPT, XLS, and PDF)”.
How to get database table metadata
Following steps are available:
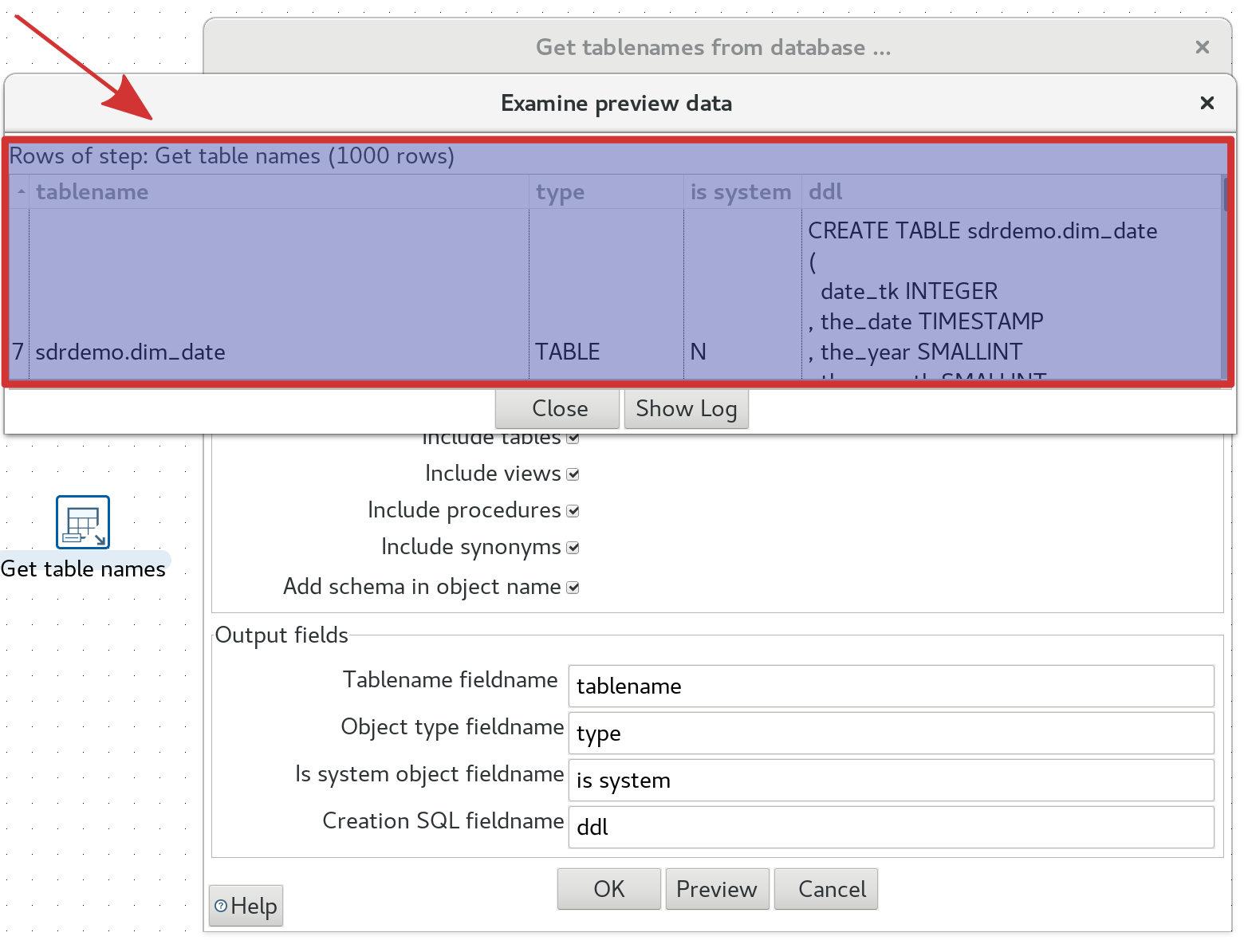
Get tables names from database:
Returns Catalogs, Schemas, Tables, Views, Procedures and/or Synonyms. You can pick which category you want to retrieve. The output includes a field which determines the object type (schema, table, etc). There is also an option available to output the DDL, so you could theoretically get hold of Column metadata as well. The DDL is returned in standard SQL format and it wouldn’t be too complex to add a parser to extract this metadata, however, there are other more convenient options available, which we will talk about in a bit.
The screenshot below shows the list of table metadata return from a PostgreSQL database. Note that we disabled the retrieval of tables and views here as you cannot do this at the same time:
Metadata structure from Stream:
A very classic approach has been to use a combination of the Table input step and Metadata structure from Stream step to get the most essential metadata. You would configure the Table input step to just source one record, something like this:
SELECT
*
FROM ${PARAM_TABLE_NAME}
LIMIT 1
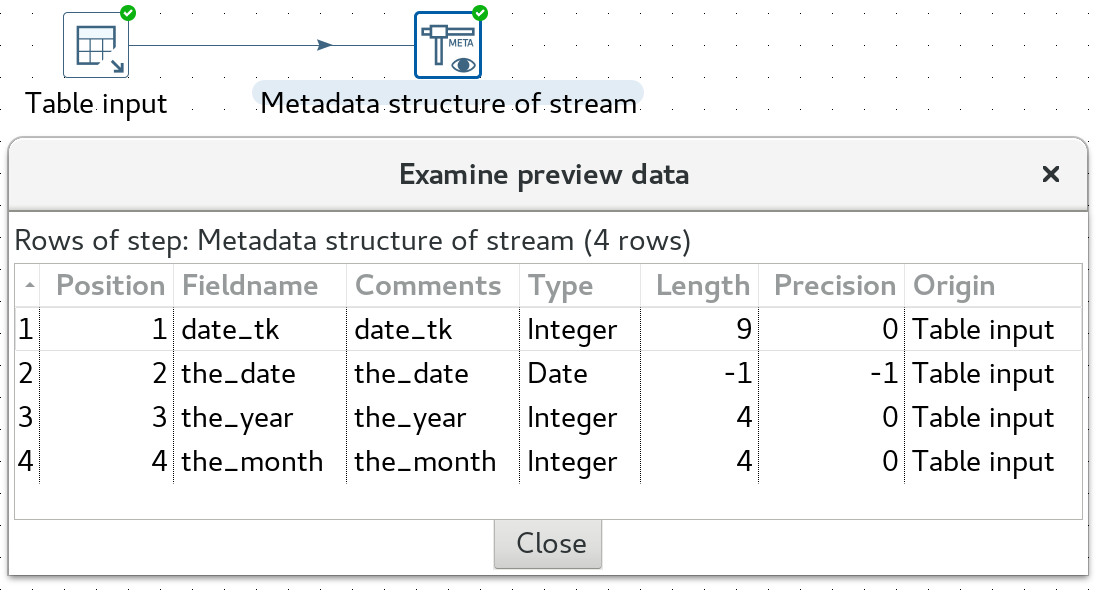
The Metadata structure from Stream can be used in various other scenarios as well.
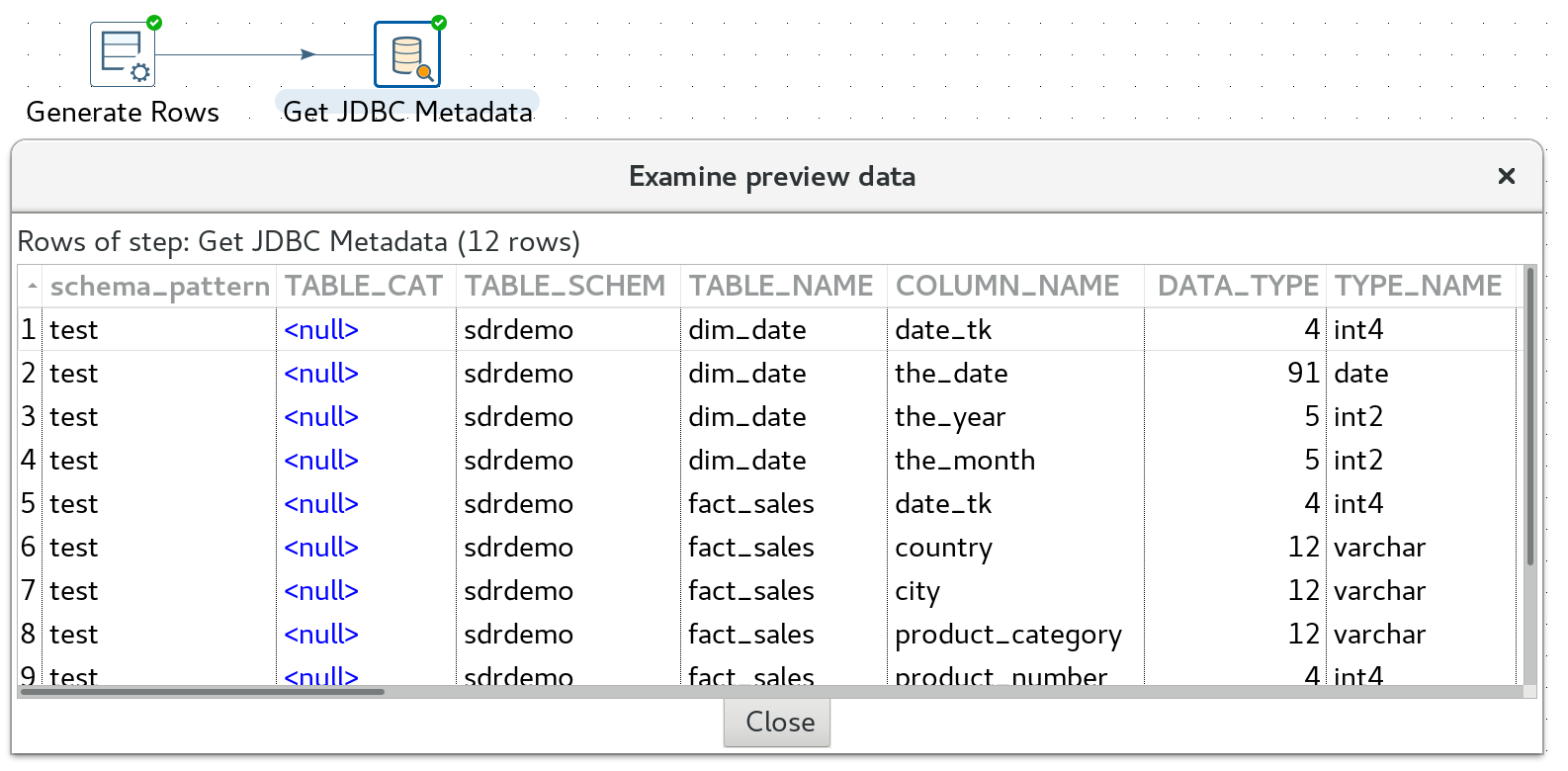
JDBC Metadata (from the Marketplace):
Returns following metadata:
- Catalogs
- Best row identifier
- Column privileges
- Columns
- Cross references
- Exported key columns
- Foreign key columns
- Primary key columns
- Schema
- Table privileges
- Table types
- Tables
- Data types
- Version columns
Blimey, that’s a lot of metadata!
Note: This step requires at least one input row, so you can in the simplest case use e.g. a
Generate Rowsstep and configure it to produce 1 row and no fields. There is also the option to configure theJDBC Metadatastep based on fields from the stream/input.
The screenshot below shows the columns for tables within the sdrdemo schema:
As you can see, there are various options of getting the required Metadata for ETL Metadata Injection, so generating extremely flexible data integration processes is finally possible.