A few weeks ago I thought about writing a blog post on Pentaho Data Integration’s Transformation Executor step - in particular about the feature to send groups of records to the sub-transformation. However, at this point, I didn’t quite envision a useful practical example.
Transformation Executor enables dynamic execution of transformations from within a transformation. This allows you to fairly easily create a loop and send parameter values or even chunks of data to the (sub)transformation. Originally this was only possible on a job level.
Yesterday when a colleague of mine, Miguel, was teaching a new colleague on how to use the Metadata Injection step, I was occasionally paying attention while debugging a Pentaho MapReduce job.
Metadata Injection: Just to mention it again (and see my other blog posts on this topic for further details): The Metadata Injection step is one of the coolest features of Pentaho Data Integration! It allows you to dynamically define the settings of a transformation step at runtime. Basically, the transformation that you initially build is just a skeleton/template and at run time you dynamically inject the settings.
At some point Miguel discovered that the Transformation Executor step was supporting sending groups of records to the sub-transformation, at which point I joined the discussion. I explained on how to build the sub-transformation for this use case: The most important point being that you have to use a Get rows from result as the start and - optionally - a Copy rows to result as the end of your stream. Using Copy rows to resultset is only required if you want to send the data back to the parent transformation (to be precise: the output of the Transformation Executor step).
Miguel then explained that in a previous project he used the Metadata Injector step to dynamically specify the metadata for text files (for the Text Input step). The metadata looked like so (simplified):
| file | field | type |
|---|---|---|
| sales | date | Date |
| sales | store | String |
| sales | amount | Number |
| stock | date | Date |
| stock | product | String |
| stock | count | Integer |
This metadata was stored centrally in a text file, the ETL process would source this data. A Group By step was used to concatenate the data for one particular file like so:
| file | fields | types |
|---|---|---|
| sales | date, store, amount | Date, String, Number |
| stock | date, product, count | Date, String, Integer |
The reason for this approach was that you can only send one row of data to each transformation. Miguel then told me that in the sub-transformation he had to (after having source the row values) use a Split fields to rows step to get the data back to its original structure. Our friend Miguel realised that using the Transformation Executor with the record group option would have simplified this setup quite a bit. Let’s have a look at this example now:
Our mission: Build a transformation which can read any text file and does something with the data - in our case we skip the last step for simplicity.
Our strategy:
Hold on - any text file? With just one transformation? Really? Are you kidding me? While at first this seems like an impossible mission, Pentaho Data Integration’s Metadata Injection step helps us to accomplish this mission.
What we need:
- One table holding all the file metadata to tell the Text File Input step what to do.
- The master: This transformation reads this metadata table and sends the group of records relevant for one particular input file to a sub-transformation.
- The metadata injector: This transformation which receives the metadata for one file and injects it into the template transformation.
- The template: This sub-transformation does the actual work: It reads the file and manipulates the data down the stream. This transformation is just a skeleton/template, meaning e.g. the Text Input step will not have any or only some settings defined.
Does this sound sane? Seeing is believing: Here is the code to the this setup! Have fun.
The Master: Sending Metadata Record Groups With the Transformation Executor
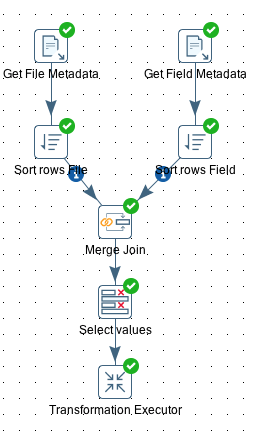
Create a new transformation called tr_master.
We decided to structure our metadata into two parts:
- Details on the file, like storage directory etc.
- Details on the fields per file.
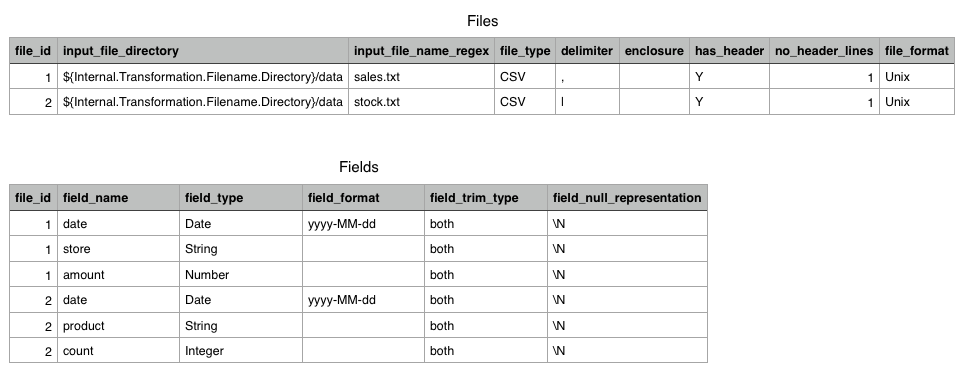
Each of these details are stored in a text file (but ideally you want to have this in a database). We source these files in our transform and join them on the file_id field.
Next we define the transformation that the Transformation Executor step should run: In our case we set File name to ${Internal.Transformation.Filename.Directory}/tr_injector.ktr.
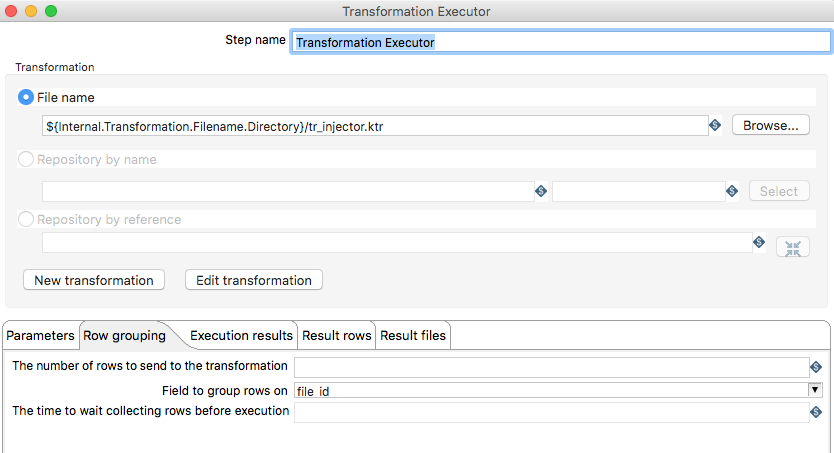
On the Row grouping tab we remove the default value of The number of rows to send to the transformation to enable the Field to group rows on option. Pick the group field, in our case file_id.
Creating the Metadata Injection Transformation
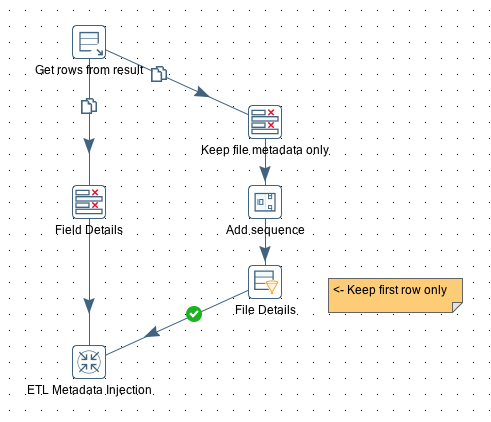
Create a new transformation called tr_injector. As in our case this transformation will be executed several times by a parent/master transformation and the metadata will be sent in record groups, we have to structure this transformation as follows:
Initially we receive the Record Group from the parent transformation via the Get rows from results step.
Open the Get rows from results step and specify all the input fields. These are all our Metadata fields:
file_id
input_file_directory
input_file_name_regex
file_type
delimiter
enclosure
has_header
no_header_lines
file_format
field_name
field_type
field_format
field_trim_type
field_null_representation
It is sufficient to specify all these fields as type string.
The output of the Get rows from result step gets copied to two streams: One which will only keep the field metadata and another one which will keep only the file metadata. As we have the file metadata duplicated several times here (for each field), we have to make sure that we only send the file metadata once to the Metadata Injection step. A simple way to do this is to add a sequence number to the rows and keep the first row only. If we had hadn’t dedupulicated the file metadata, the Skeleton transformation would have been executed several times.
Both streams finally join in the ETL Metadata Injection step.
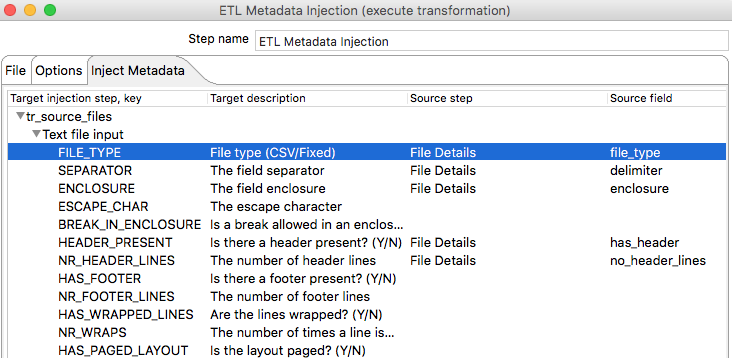
Open the ETL Metadata Injection step and specify as transformation template ${Internal.Transformation.Filename.Directory}/tr_source_files.ktr. Then click on the Inject Metadata tab where we can map our metadata fields to the step settings. Spoon will show any steps from the sub-transformation which accept Metadata Injection. It is important to understand that you do not have to define a mapping for every setting, only the ones that you want to provide dynamically!
To create a mapping, just click on the left hand side of the row, e.g. FILE_TYPE and Spoon will provide you a dialog to select the corresponding field from the input stream.
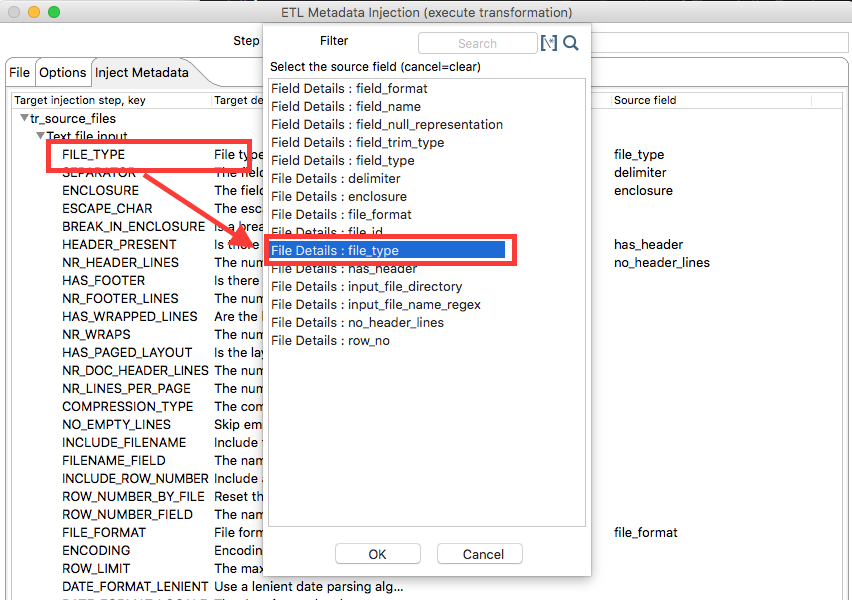
Once the mapping is defined, the window looks like this:
Create the Main Transformation Skeleton
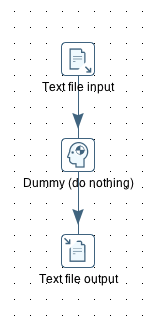
Create a new transformation and call it tr_source_files. In our case we just add the following steps:
- Text file input
- Dummy
- Text file output
Create a hub between all the steps. The important point here is that you do not fill out any of the step settings (or just the settings that you do not want to dynamically inject). We only added the Text file output step as we are curious to see the output: In this case we define the output filename and we enable the append option. We do not specify any fields, as we want to output any fields that come along.
We have intentionally kept this transformation extremely simple, to just focus on the main setup of this process.
Finally, execute the tr_master.ktr transformation with the provided files (Download here) and you should fine one output file with the content of all input files.