Every now and then I am thinking about the snapshot strategy I described about a year ago. I am still not quite happy about it. It’s a huge new data generating monster (well it actually creates a massive amount of output data based on the relatively compact input dataset). It sometimes puzzles me that OLAP tools don’t have a better way to handle snapshots. Or maybe there is a better strategy to do this?!
Just to recap: If you are asked to provide a daily snapshot, your ETL has to generate a row for every day for every little thing that you are trying to keep track of. This is kind of the consequence of providing this data in a cube: You have to have a (fact/snapshot) row available for a particular day in order to join it to any other dimension.
The problem of having to produce these artificial records is not going away for now (unless there is better support for this by OLAP tools), so we have to find better ways to generate the snapshot. However, every now and then I ask myself: What if we have to generate a snapshot on a by second grain (as opposed daily), how will we cope with generating so much data? There must be a better approach to do this. This is certainly an extreme situation, however, it pronounces the problem we have with current approach.
So how could we possibly make things a bit easier? What if we tried to implement everything in SQL, so that we can i.e. run it easily on Hive? The main challenge here is actually how to create the artificial clones?
For this example we assume that we are tracking the status of cases. Say we have a case which got opened on 2016-02-01 and changed its status to assigned on 2016-02-05.
Coming back to our example: To create a daily snapshot, we have to clone the record from 2016-02-01 3 times: For 2016-02-02, 2016-02-03 and 2016-02-04. The key here is to treat this data as a Slowly Changing Dimension Type 2, so assign a valid_from and valid_to to each event. We store this data in a table called dim_events. It’s not really necessary to make this table a fully qualified dimension - the idea is just to treat the data in a similar fashion.
Showing state changes: If you want to show state changes in your reports, e.g. The case moving from status
opentoclosed, you can introduce aprev_statuscolumn for this table. Whyprev_statusand notnext_status? This is a design decision and might vary on your use case: The advantage ofprev_statusis that it makes to record immutable, which is ideal for Hadoop. However, if you already have a process in place to maintain avalid_tofor the same table, then you might as well instead maintain anext_statusfield.
So what about creating the clones then for the actual snapshot table? Actually, this can be very easily achieved by joining to the Date Dimension. We just have to use the valid_from and valid_to from our dim_events table and retrieve the respective days from the dim_date table using WHERE clause. Based on the example above, we have one record from dim_event being joined to 4 records from dim_date, so in the end we will get 4 records returned. We enrich the result by adding a constant of 1 for aggregation purposes (not strictly required).
I prototyped the solution quickly with PostgreSQL:
DROP SCHEMA IF EXISTS snapshot_example CASCADE;
CREATE SCHEMA snapshot_example;
CREATE TABLE snapshot_example.dim_date AS
WITH RECURSIVE date_generator(date) AS (
VALUES (DATE '2016-01-01')
UNION ALL
SELECT date+1 FROM date_generator WHERE date < DATE '2017-01-01'
)
SELECT
CAST(TO_CHAR(date,'YYYYMMDD') AS INT) AS date_tk
, date AS the_date
, EXTRACT(DAY FROM date) AS the_day
, EXTRACT(MONTH FROM date) AS the_month
, EXTRACT(QUARTER FROM date) AS the_quarter
, EXTRACT(YEAR FROM date) AS the_year
FROM
date_generator
;
SELECT * FROM snapshot_example.dim_date LIMIT 20;
-- treat events as slowly changing dimension
CREATE TABLE snapshot_example.dim_events
(
event_tk BIGINT
, case_id BIGINT
, valid_from INT
, valid_to INT
, event_status VARCHAR(20)
)
;
INSERT INTO snapshot_example.dim_events VALUES
(1,2321, 20160201, 20160205, 'open')
, (2,2321, 20160205, 20160207, 'assigned')
, (3,2321, 20160207, 20160208, 'closed')
;
-- create snapshot by exploding the events
CREATE TABLE snapshot_example.snapshot AS
SELECT
case_id
, event_tk
, date_tk AS snapshot_date_tk
, valid_from
, valid_to
, event_status
, 1 AS quantity
FROM snapshot_example.dim_events f
INNER JOIN snapshot_example.dim_date d
ON
d.date_tk >= f.valid_from
AND d.date_tk < f.valid_to
;
SELECT * FROM snapshot_example.snapshot LIMIT 20;
An the result looks like this (valid_from and valid_to are only part of the result to facilitate QA and should be removed thereafter):
| case_id | event_tk | snapshot_date_tk | valid_from | valid_to | event_status | quantity |
|---|---|---|---|---|---|---|
| 2321 | 1 | 20160201 | 20160201 | 20160205 | open | 1 |
| 2321 | 1 | 20160202 | 20160201 | 20160205 | open | 1 |
| 2321 | 1 | 20160203 | 20160201 | 20160205 | open | 1 |
| 2321 | 1 | 20160204 | 20160201 | 20160205 | open | 1 |
| 2321 | 2 | 20160205 | 20160205 | 20160207 | assigned | 1 |
| 2321 | 2 | 20160206 | 20160205 | 20160207 | assigned | 1 |
| 2321 | 3 | 20160207 | 20160207 | 20160208 | closed | 1 |
Keep in mind that with a snapshot you only look at one day at a time, we do not aggregate the final figures across days! The main question that this output answers is the following: “How many cases were in status X on day Y”?
Note: If for some reason you also have to count the days and/or working days that a certain case stayed in a given status, you can just simply add a binary flag (using an
TINYINTrepresentation of0and1) to the date dimension and enrich the join ofdim_eventanddim_datewith these flags, which can then just be aggregated in some form (so perform some additional aggregation across days upfront for the final output … you could use a windowed function in example):
SUM(is_working_day) OVER (PARTITION BY ... ORDER BY ...)
The final join helps us to materialise the view which the OLAP/Cube tool requires.
Note: When implementing the solution on HDFS there is currently no way to update records, so keeping the
valid_toupdated causes an issue. You could opt for Kudu, which allows updates. However, there is still a way to achieve this on Hadoop: 1) Either you keep thevalid_fromonly and generate a materialised view using a windowing function which provides thevalid_toas well. This works for smaller tables only. 2) Or you use the same approach as in 1), but store any properly closed records in a dedicated partition (let’s call the partitionstaticorclosed) and the other records (the ones with avalid_toin the future) in another dedicated partition (let’s call itopen). If you get an update to an open record, you move the old record with the “updated”valid_toto thestatic/closedpartition and insert the new record into theopenpartition. This way you only have to run an “update” against a smaller batch of data.
The output of the query above might be in some cases a bit too granular, but performing an aggregation of top of this is very easy.
Pentaho Metadata Layer
Just as a side node, if you were ever to implement a similar model with the good old Pentaho Metadata Editor, you could define the two tables in the model and a complex join between them which could look something like this:
AND(["BT_DIM_DATE_DIM_DATE.BC_DIM_DATE_DATE_TK"] >= ["BT_DIM_EVENTS_DIM_EVENTS.BC_DIM_EVENTS_VALID_FROM"] ;
["BT_DIM_DATE_DIM_DATE.BC_DIM_DATE_DATE_TK"] < ["BT_DIM_EVENTS_DIM_EVENTS.BC_DIM_EVENTS_VALID_TO"])
This replicates the same logic we applied in the very last logic above.
A screenshot of this complex join is shown below:
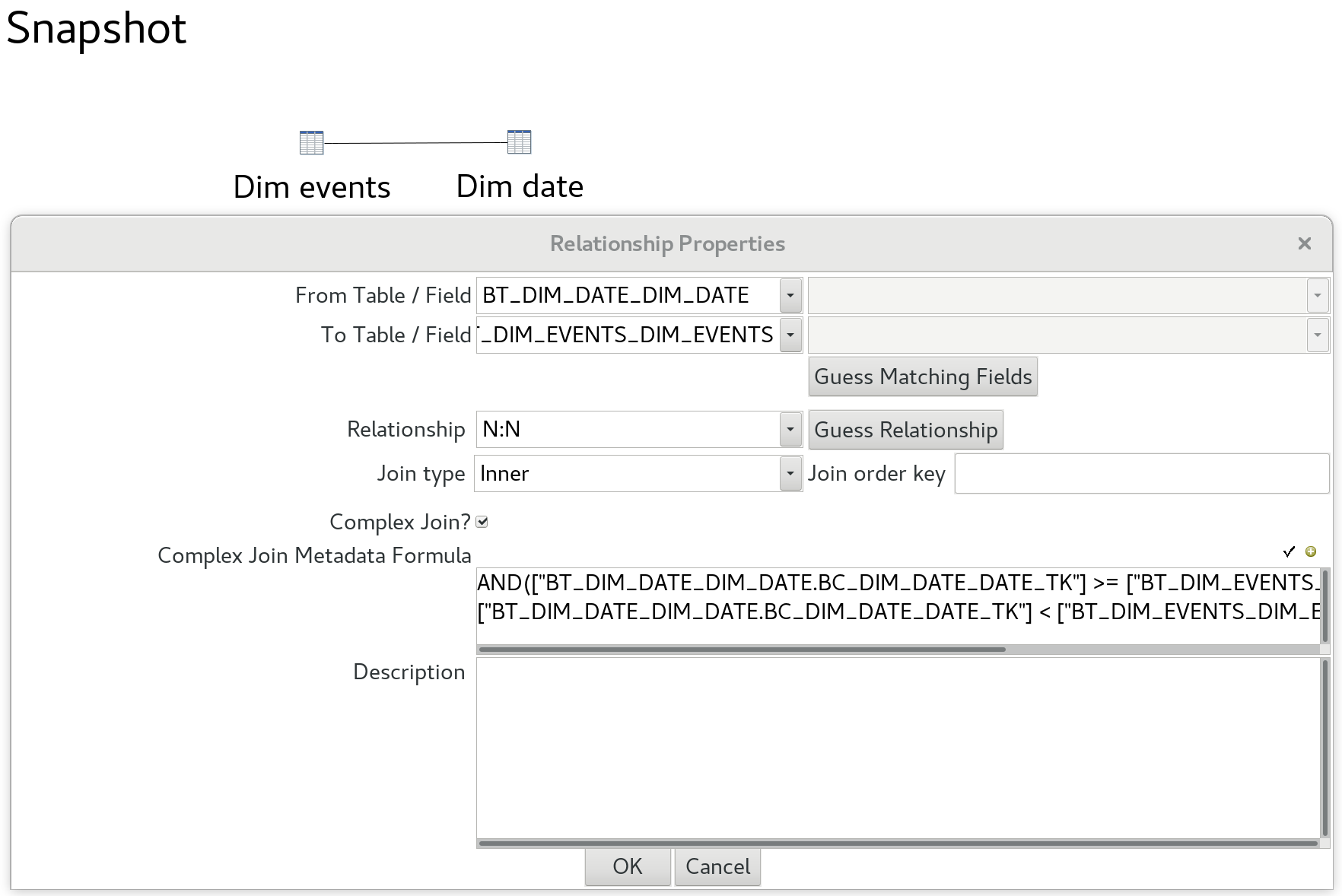
This approach puts a lot of weight onto the database, so if you are dealing with a lot of data, it might be better to materialise the result of this join upfront.
Let’s extend our sample data a bit (complete data set shown, not just additional records):
INSERT INTO snapshot_example.dim_events VALUES
(1,2321, 20160201, 20160205, 'open')
, (2,2321, 20160205, 20160207, 'assigned')
, (3,2321, 20160207, 20160208, 'closed')
, (4,2322, 20160202, 20160204, 'open')
, (5,2322, 20160204, 20160207, 'assigned')
, (6,2322, 20160208, 20160208, 'closed')
;
If we were just interested in understanding, how many cases/events there were within a certain period and event status, then we can add a new field in the metadata model at the table level called Count Events and define as Aggregation Type Count and as Formula event_tk.
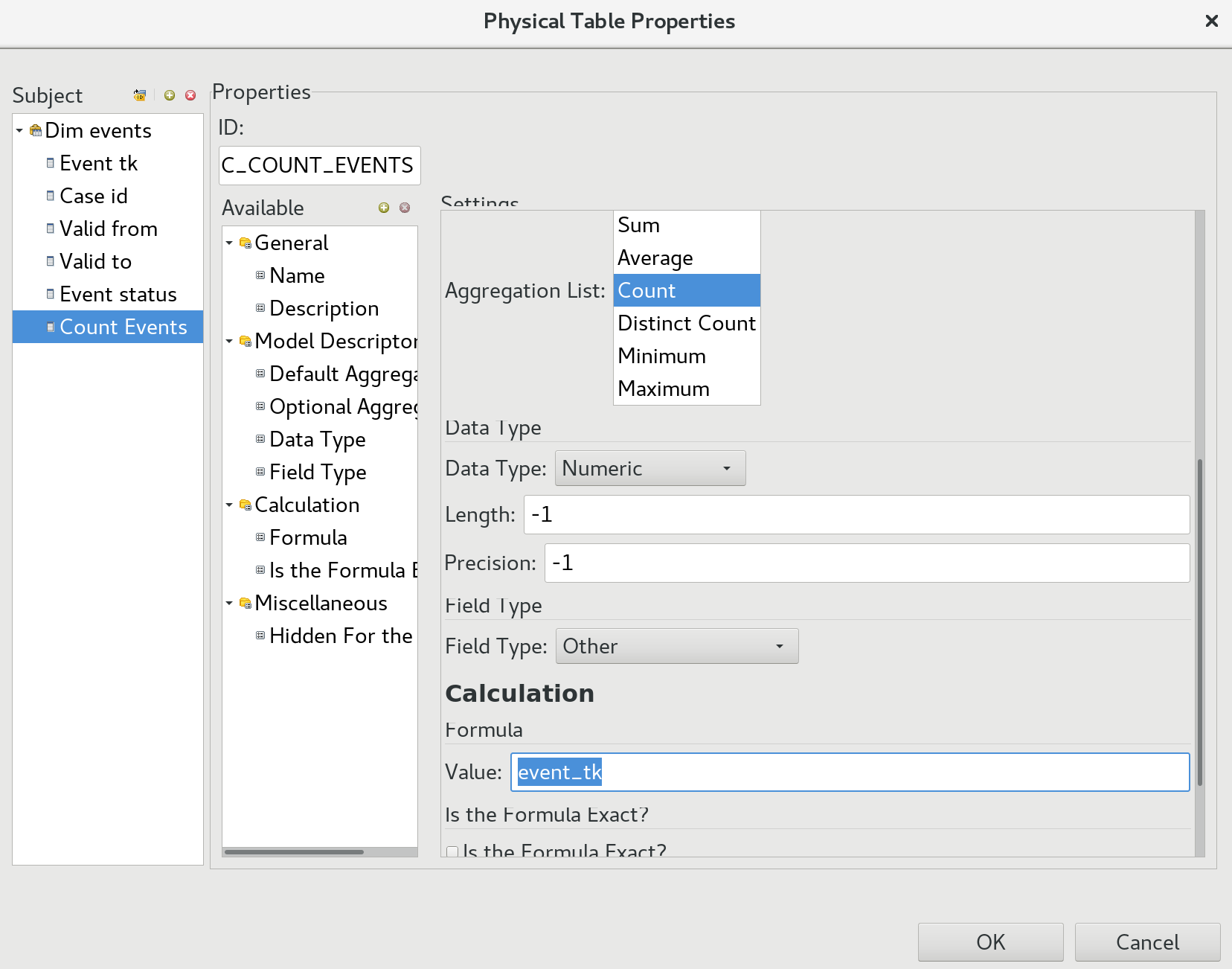
Alternatively we could also just add a counter to our base table directly.
We can test if we generate the correct figures by using the built-in query builder:
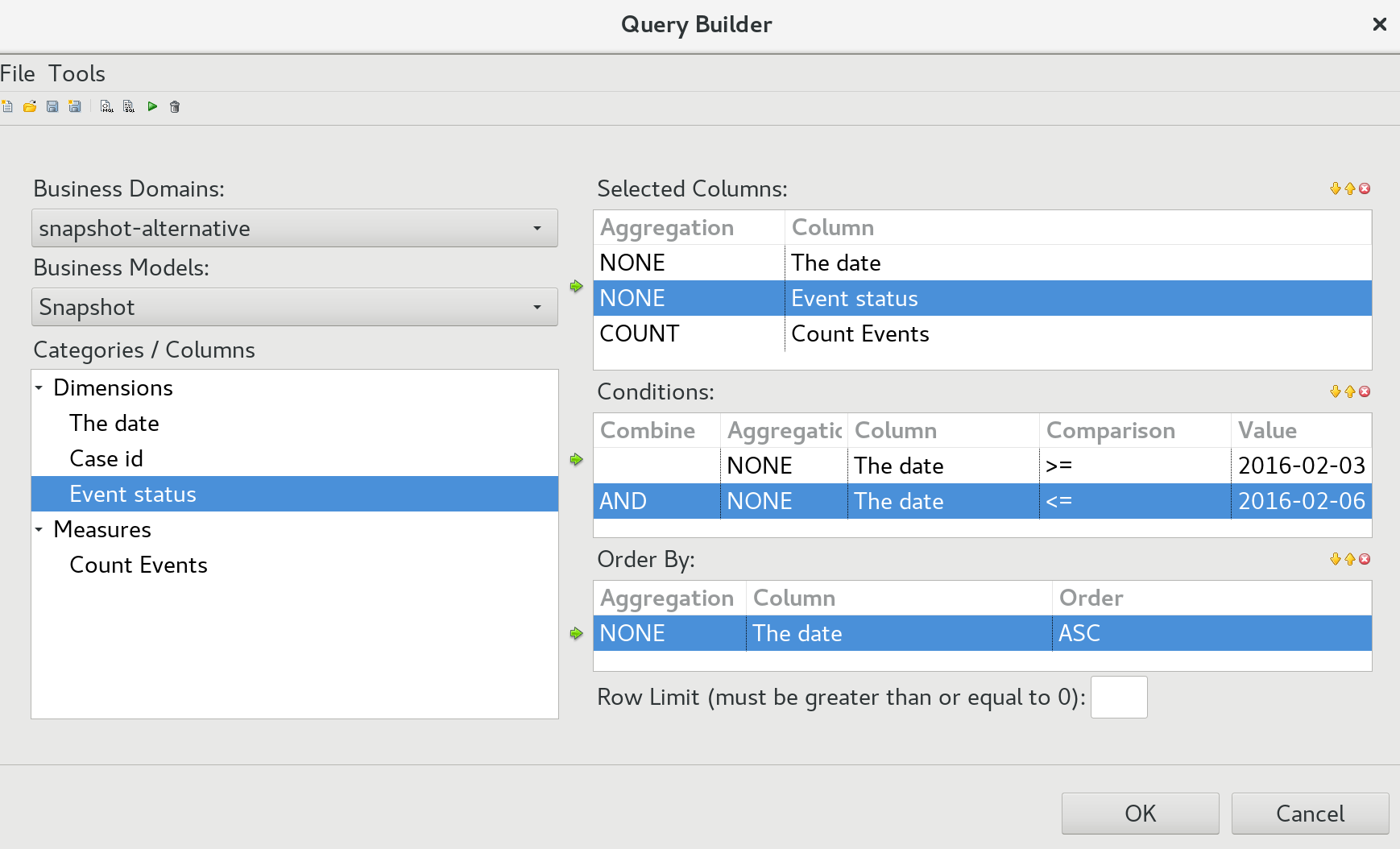
And the result looks like this:
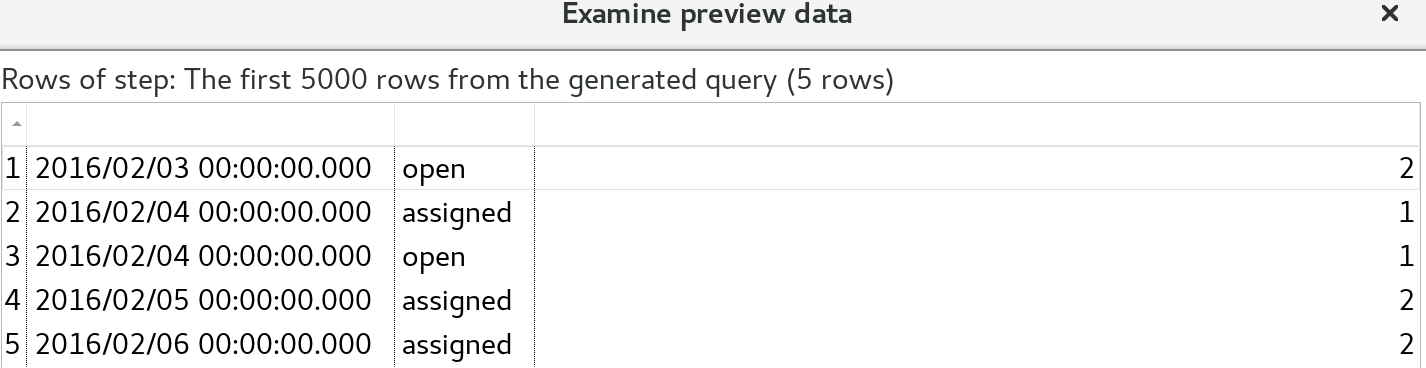
Which is in line with our expectations.
The sample files are available here.