At the last Pentaho London User Group (PLUG) meetup PDI founder Matt Casters mentioned briefly that he started work on streaming enhancements for PDI. PDI is a streaming engine at heart. This streaming plugin exposes the stream via a web service. Imagine you have a never ending transformation and you want to check which data is currently in the stream: You can just call the REST endpoint. If REST is not a good fit for your project, you can even query the streaming cache with standard SQL. Now listen again - this is really cool - you can actually expose the stream via a Pentaho Data Service, which can be queried by any SQL client tool!
As always you can find the code for this example on my Github repo.
Initial Setup
Download PDI from here and extract it in a convenient directory. E.g.:
$ cd /Applications/Development/
$ cp ~/Downloads/pdi-ce-6.1.0.1-196.zip .
$ unzip pdi-ce-6.1.0.1-196.zip
$ mv data-integration pdi-ce-6.1
Go to PDI Streaming Plugin and download from the latest release the pentaho-pdi-streaming-TRUNK-SNAPSHOT.jar. Copy the jar file into PDI’s plugins/ folders:
$ cd /Applications/Development/pdi-ce-6.1/
$ mkdir plugins/pentaho-pdi-streaming
$ cp ~/Downloads/pentaho-pdi-streaming-TRUNK-SNAPSHOT.jar plugins/pentaho-pdi-streaming
Note: Each plugin jar file must reside within its own folder within the plugin directory, otherwise conflicts may arise.
Start Spoon (PDI’s GUI):
$ chmod -R 700 *.sh
$ sh ./spoon.sh
Creating a simple Streaming Process
Create a new transformation called simple-stream using a Generate Rows step with Never stop generating rows enabled, the Generate random value step and finally a Dummy step.
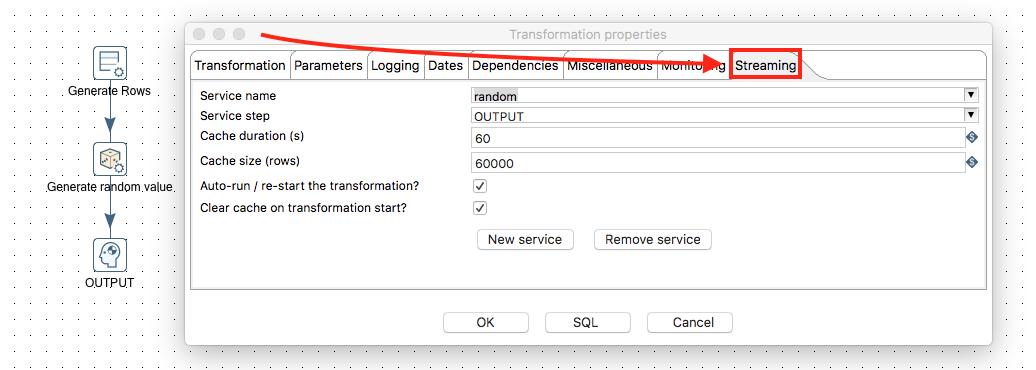
Defining the Streaming Settings
- Press
CMD+TorCTRL+T(or alternatively right click and choose Transformation Settings). - Click on the Streaming tab.
- Click on the New Service button at the bottom and name the service My Streaming Service.
- Choose the Dummy (do something) step as the Service step.
- Set Cache duration(s) to
60. - Set Cache size (rows) to
60000.
Starting the Carte server and Registration with Spoon
Note: If you have a PDI EE version with a running Carte server, the transfromation will automatically run once you confirm the details in Transformation properties > Settings. In this case you do not have to follow the next steps.
Back on the command line, in the PDI root directory, run:
sh ./carte.sh localhost 8099
It will take a bit until the server started up. Open following URL in your favourite web browser:
http://localhost:8099
The default username is cluster and the default password is cluster.
Back in Spoon we will register the Carte server now. This will enable us to use Spoon’s GUI to start the transformation on the server. (This is not the recommended approach for production use).
- Click on the View tab on the left hand side.
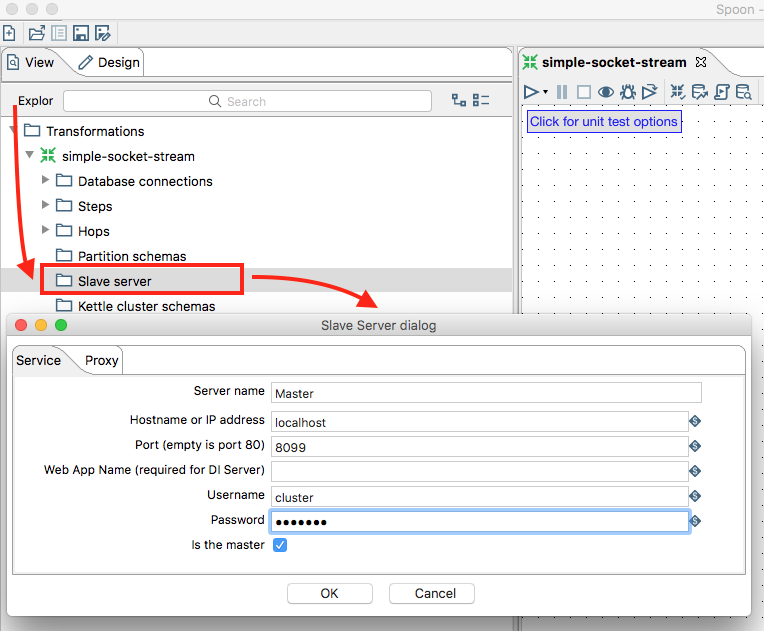
- Right click on the Slave servers folder and choose New.
-
Fill out all the required details. Make sure you tick Is the master.
-
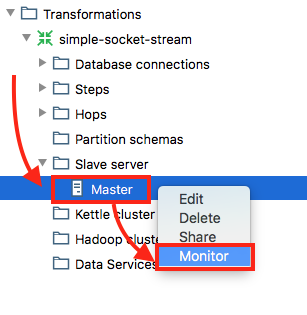
Then expand the tree to see the newly created Slave Server node. Right click on it and choose Monitor. This will open a new tab which will show you the currently running jobs and transformations.
Now we can execute our transformation remotely:
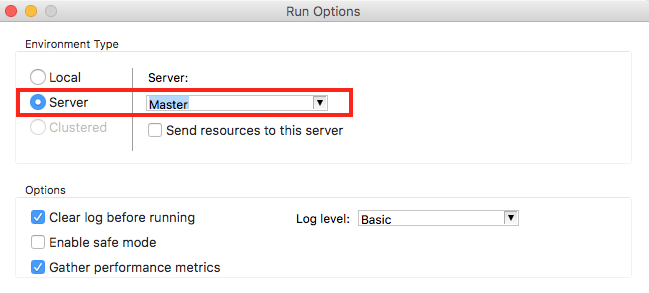
- Go back to your transformatio and click the Execute button.
-
In the option choose Server. Confirm by clicking Run.
This will automatically bring you to the monitoring tab. Click on the Refresh button to update the stats.
Now open your favourite web browser and input this URL:
http://localhost:8099/kettle/listStreaming/
This should return the available streaming services.
In my case it took quite a bit until the service showed up.
Monitoring using REST Endpoints
There are quite a few options available with the REST endpoints, which are listed below:
| Description | Service Endpoint |
|---|---|
| List Streaming Services | http://localhost:8099/kettle/listStreaming/ |
| Get last X rows | http://localhost:8099/kettle/getStreaming?service=<serviceName>&last=<number> |
| Get last X ms worth of data | http://localhost:8099/kettle/getStreaming?service=<serviceName>&lastPeriod=<number> |
| Start of range for numbered rows | http://localhost:8099/kettle/getStreaming?service=<serviceName>&fromId=<number> |
| End of range for numbered rows | http://localhost:8099/kettle/getStreaming?service=<serviceName>&toId=<number> |
| Max number of new rows to retrieve (to keep clients reactive) | http://localhost:8099/kettle/getStreaming?service=<serviceName>&new=<number> |
| Maximum number of seconds to wait for new data | http://localhost:8099/kettle/getStreaming?service=<serviceName>&maxWait=<number> |
There are quite a few interesting options, right?!
Querying the Stream with SQL
Yes, you read it correctly: Querying the Stream with SQL! The streaming plugin comes with a new step called Get Streaming Cache. We can then expose this step (or any thereafter) as a Pentaho Data Service.
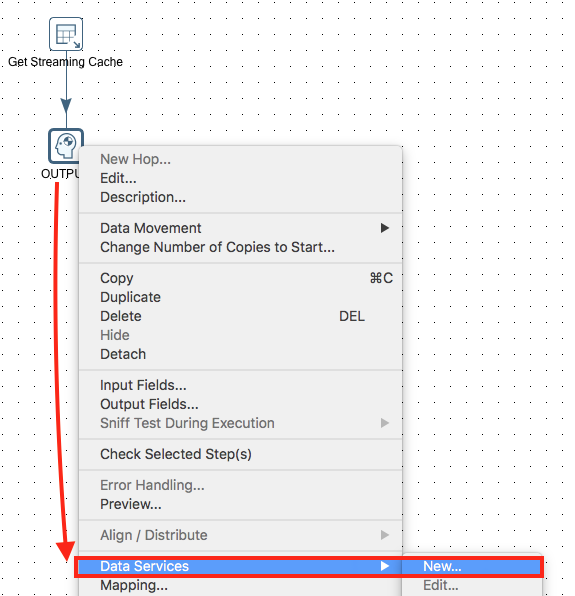
Create a new transformation called simple-stream-data-service and add a Get Streaming Cache step. Double click on it. Most info is already provided: Just pick our streaming service from the pull down list and correct the base service URL to use port 8099. Then add a Dummy step and link the two. Rename the step to Output. Right click on the Dummy step and choose Data Service > New:
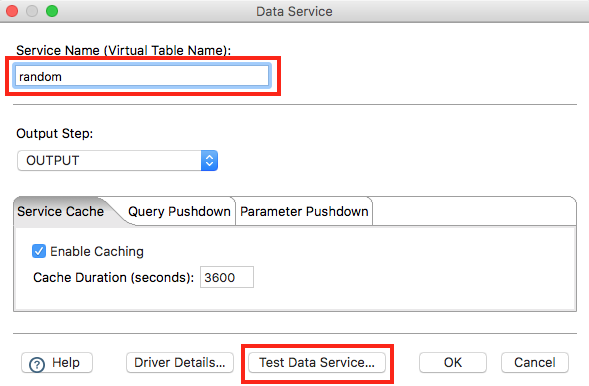
Specify as Service Name random and then click on Test Data Service:
And the result looks something like this:
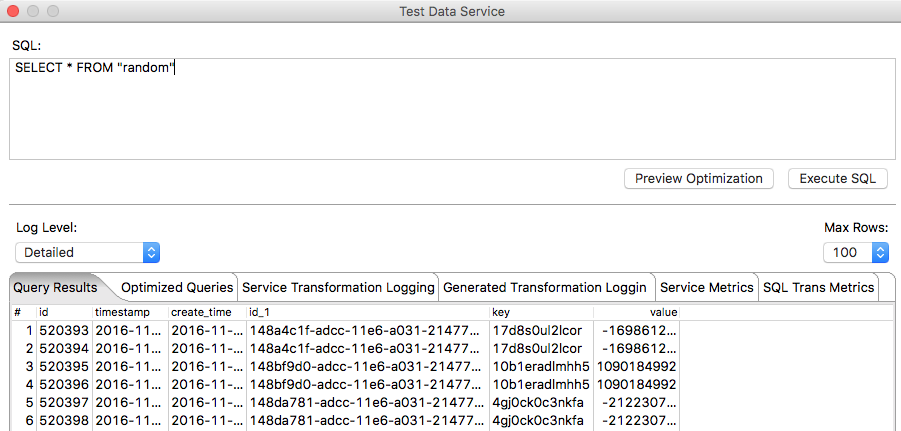
Quite amazing, right?! We just queried the stream with SQL!
Additional Notes
Many thanks to Matt Casters for providing all the in-depth info on this plugin!
If you hook up the enterprise repository the metastore artifacts will go there and everything connected (including Carte) will know about it and the service will start immediately after you configure it.
If you have a file based (non repository) setup, local ~/.pentaho/metastore objects have to be copied to other envirnments manually.
he location of the Metastore can be configured via the PENTAHO_METASTORE_FOLDER environment variable. You will have to change spoon.sh to take this variable into account. Simple add ` -DPENTAHO_METASTORE_FOLDER=$PENTAHO_METASTORE_FOLDER to the end of the OPT=` section:
Before:
OPT="$OPT $PENTAHO_DI_JAVA_OPTIONS -Dhttps.protocols=TLSv1,TLSv1.1,TLSv1.2 -Djava.library.path=$LIBPATH -DKETTLE_HOME=$KETTLE_HOME -DKETTLE_REPOSITORY=$KETTLE_REPOSITORY -DKETTLE_USER=$KETTLE_USER -DKETTLE_PASSWORD=$KETTLE_PASSWORD -DKETTLE_PLUGIN_PACKAGES=$KETTLE_PLUGIN_PACKAGES -DKETTLE_LOG_SIZE_LIMIT=$KETTLE_LOG_SIZE_LIMIT -DKETTLE_JNDI_ROOT=$KETTLE_JNDI_ROOT"
After:
OPT="$OPT $PENTAHO_DI_JAVA_OPTIONS -Dhttps.protocols=TLSv1,TLSv1.1,TLSv1.2 -Djava.library.path=$LIBPATH -DKETTLE_HOME=$KETTLE_HOME -DKETTLE_REPOSITORY=$KETTLE_REPOSITORY -DKETTLE_USER=$KETTLE_USER -DKETTLE_PASSWORD=$KETTLE_PASSWORD -DKETTLE_PLUGIN_PACKAGES=$KETTLE_PLUGIN_PACKAGES -DKETTLE_LOG_SIZE_LIMIT=$KETTLE_LOG_SIZE_LIMIT -DKETTLE_JNDI_ROOT=$KETTLE_JNDI_ROOT -DPENTAHO_METASTORE_FOLDER=$PENTAHO_METASTORE_FOLDER"
PDI Caching is just local in-memory cache. There is currently no support for other caching technologies like Hazelcast or so.