Resources
- Project Homepage
- GitHub
- Docu on GitHub
- Jira: To create a new bug report or feature request, simply press
Conce on the Kanban board. - Forum
- Chat
- WebHop
- Docker
- Beam Examples: Once cloned you can point to that directory as an
ENVIRONMENT_HOME. - Hop Ultimate Import Tool: Converts PDI/Kettle jobs and transformations to Hop pipelines and workflows.
History
Hop is a new open source data integration tool which builds on long history:
Hop 0.10 marks the first official release of Project Hop, which was founded last year by Matt Casters and KnowBI (Bart and Hans). It’s a fork of PDI. It offers a good chance to clean up and improve features that have been on the backlog for decades. It’s also a great opportunity to introduce new concepts and ideas. The first release has been mainly about cleaning up the code base and making it more modular as well as introducing UI improvements, both of which are very welcome by long-term PDI/Kettle users.
Which brings us to the point where we should explain what PDI and Kettle are: KETTLE was originally developed by Matt Caters as an open source ETL tool and subsequently integrated into the Pentaho stack and renamed to Pentaho Data Integration (PDI). Many years later Pentaho was acquired by Hitachi and since then one could get the impression that development efforts on the product have stalled quite a bit.
Hop into a new World
Chances are that you’ve previously used Kettle/PDI, so this section is more a summary of what has changed so far:
What’s new
Package Size: Hop is a lean machine! Down to 167MB compared to the previous 1.5GB (PDI v8.3). Naturally we are comparing apples with oranges here - but in a nutshell a lot of stuff was removed that isn’t a core feature (e.g. Karaf).
Everything is a plugin: Quite some work has gone into refactoring the code so that each step is a plugin. In other words, everything is modular now. This means that you can fine-tune Hop to your requirements.
Long live the container: As a consequence of the above, Hop is a much better fit for a containerised world than PDI. Now we can build slim Docker images that only include what we require. It’s a world without all the ballast.
Start-up Time: Another consequence of the new lean setup is that the start-up time is significantly reduced. Finally I don’t have to brew a coffee any more while waiting for the GUI to start up. (This doesn’t only apply to the GUI, also the command line utilities are much faster).
Apache Beam support out-of-the box: Now this is a big one! It opens the door to a wide variety of engines (Flink, Spark, etc). Hop is one of the first GUI driven pipeline designers for Apache Beam!
Environment support built-in! Define all the variables in one file and Hop will pick it up. Gone are the days when you had to built your custom solution for this!
Unit testing support built-in! Also know as Hop datasets, this feature accelerates quick prototyping and testing.
UI Changes:
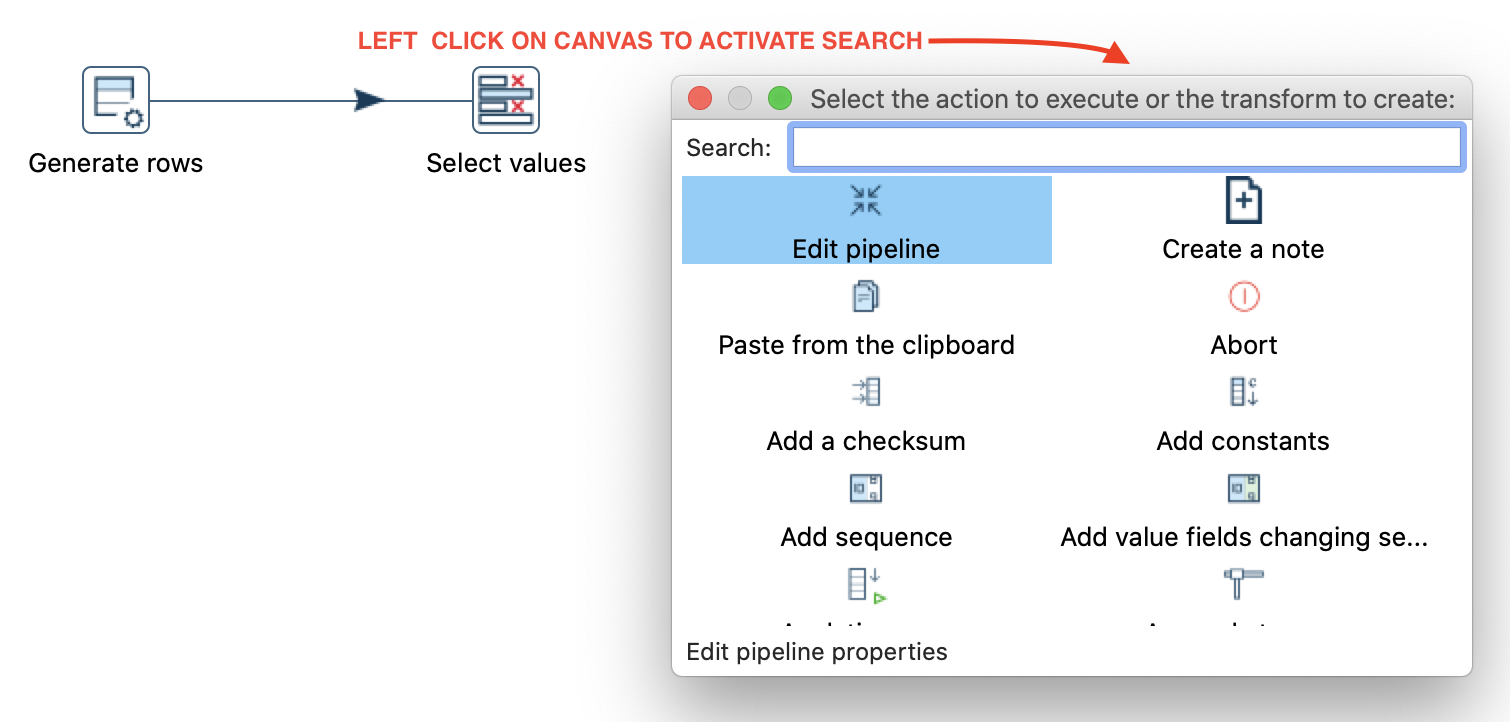
- A new quick search function allows you to easily search for transforms/steps and functions that were previously available via the context menu (e.g. preview the output of a step). Quick search can be activated by left clicking on the canvas. This replaces the context menu that could previously be activated by right clicking on a step as well as the left hand side steps panel. Give Quick Search a try - it’s a joy to use!
- All UI elements are all working now. Previously some UI element, like the repository picker, were not working on some environments.
- You will notice a few other changes … go ahead and explore the GUI yourself to get an impression of the changes.
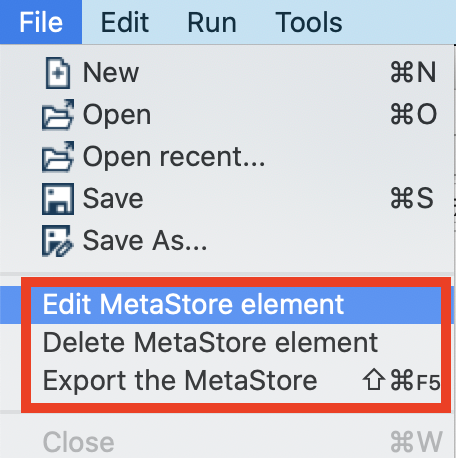
Full power to the Metastore: Previously only a few configuration details were stored in the Metastore. Now database connections, Carte details, Pipeline Run Command and Partition Schema are also stored in the Metastore, which makes the configuration much more uniform. There are a few new menu entries available to work with the Metastore:
One command line utility: Previously the kitchen utility was used to execute jobs /workflows and the pan utility to execute transformations/pipelines. The new kid in town, hop-run, consolidates the functionality of both.
Hop VS PDI
This is a comparison between Hop and PDI:
New Terminology
| Hop | PDI |
|---|---|
| pipeline | transformation |
| transform | step |
| (work)flow | job |
| action | job entry |
File Extensions
| Hop | PDI |
|---|---|
hpl (Hop PipeLine) |
ktr |
hwf (Hop Workflow) |
kjb |
Command Line Utilities
The new utility names are all about making the usage more intuitive:
| Hop | PDI | Purpose |
|---|---|---|
hop-encrypt.sh |
encr.sh |
utility to encrypt passwords |
hop-gui.sh |
spoon.sh |
utility to start GUI for designing pipelines/transformations and workflows/jobs |
hop-run.sh |
kitchen.sh and pan.sh |
utility to execute pipelines/transformations and workflows/jobs |
hop-server.sh |
carte.sh |
utility to start webserver |
hop-translator.sh |
not available | utility to help translate UI text |
Hop Config
PDI used to store most config artefacts in ~/.kettle. For Hop these artefacts live under <hop>/config.
An alternative path can be configured via the HOP_HOME env variable, e.g.:
export HOP_HOME=/tmp
./hop-gui.sh
GUI
Defining Parameters: In PDI this is done via the job or transformation settings. In Hop, use the Search function to bring up Edit Pipeline or Edit Workflow.
Can I open PDI files in Hop and vice versa?
No, not necessarily. It’s very likely that the file XML structure changes, as it already did with Hop workflows (e.g. the entry tag was replaced with the action tag). Overall I find this is also the correct direction since this gives the Hop team the option to introduce new features without depending on any PDI development.
How execute Hop Workflows and Pipelines
As we learnt, there is only one command in the Hop world to execute a workflow or a pipeline. Example:
${DEPLOYMENT_PATH}/hop/hop-run.sh \
--file=${HOP_FILE_PATH} \
--runconfig=${HOP_RUN_CONFIG} \
--level=${HOP_LOG_LEVEL} \
--parameters=${HOP_RUN_PARAMETERS} \
2>&1 | tee ${HOP_LOG_PATH}
./hop-run.sh \
--file=/path/to/workflow.hwf \
--runconfig=your-run-config \
--parameters=PARAM_TEST=Hello,PARAM_TEST_2=Goodbye
It’s all about Community
Project Hop needs a vibrant community. It’s an open source project where everyone can contribute, e.g. by:
- submitting bugs to Jira
- write documentation
- help coding/implementing features
- etc
Give Project Hop a try and maybe this sparks your enthusiasm to contribute to this project!
Other useful bits
How to check the version
Look for the lib/hop*.jar file.